
[Python] 将csv文件中单个列的多个value拆分成多个列的单个value
很久没有更新博客了,最近handle了一个项目需要处理大量csv文件,需求是将csv文件中某单个列的多个values(该多个vaules以回车分隔)拆分成多个相同列的单个value,由于python在处理脚本先天比shell更有优势,这里把自己的最近学到python知识加以应用,编写了一个脚本,供大家参考.
#!/usr/bin/env python
import csv
import sys
# Define the duality list
Csv_content_edited = []
# Define the file that needs to be handled.
try:
file_name = sys.argv[1]
new_file_name = file_name.split('.')[0] + '_new.' + file_name.split('.')[1]
except IndexError:
pass
# Define the collumns that need to be dealt with.
Field = ['Affects Version/s','Fix Version/s','Component/s']
"""
Search the index numbers of each components of "Field" list in the first row of csv file,
return the dic["field value":"the index of first_row"]
"""
def search_field_index(field, first_row):
fields_dic = {}
for x in first_row:
if x in field:
fields_dic[x] = first_row.index(x)
return fields_dic
'''
Find the maximum value number of each "Field" components in "Csv_content_edited" list,
then insert the actual number of the columns after each "Field" columns.
'''
def insert_max_col(field_index,Field_val):
# Define the list stored maximum number of the value of the field
index_len = []
# Define the list stored the value of the field
index_val = []
# Recursive the row from 2 ~ max of the csv field
for r in range(1,len(Csv_content_edited)):
# Deal with special string
c = repr(Csv_content_edited[r][field_index]).split("\\r")
index_len.append(len(c))
index_val.append(c)
# The maximum component of the "index_len" list
max_index_len = max(index_len)
# Clear " " and "'" string which are in the head or tail of each "index_val" components.
for iv in range(0,len(index_val)):
for _iv in range(0,len(index_val[iv])):
index_val[iv][_iv] = index_val[iv][_iv].strip(' \'')
# insert null value collumn after the field from "Field" list to the "Csv_content_edited" list
for i in range(0,len(Csv_content_edited)):
for m in range(0,max_index_len - 1):
Csv_content_edited[i].insert(field_index + m + 1,'')
# Update the first row of "Csv_content_edited" list to the field components from "Field" list
for i1 in range(field_index,field_index + max_index_len):
Csv_content_edited[0][i1] = Field_val
# Update the rest rows of "Csv_content_edited" list to the field components from "index_val" list
for i in range(1,len(Csv_content_edited)):
for i2 in range(field_index,field_index + max_index_len):
try:
Csv_content_edited[i][i2] = index_val[i-1][i2 - field_index]
except IndexError as s:
pass
# return Csv_content_edited[3],index_val,max_index_len
# return len(Csv_content_edited),len(index_val)
# print max_index_len
# print index_val[2][0]
# return len(index_val[2])
# Read and deal with the csv file.
def readContent(file_name):
# Read the csv file,then put it into list.
with open(file_name, 'r') as csvfile:
csv_reader = csv.reader(csvfile, delimiter=',')
for row in csv_reader:
if row[0] == 'Key':
first_row = []
first_row = row
# insert first row of csv to the list
Csv_content_edited.append(first_row)
else:
# insert rest row of csv to the list
Csv_content_edited.append(row)
else:
# Obtain all current "Field" index in "Csv_content_edited" list
fields_index = search_field_index(Field,first_row)
# Obtain the index of "Affects_Version" in in "Csv_content_edited" list
Affects_Version_index = fields_index[Field[0]]
# insert the matching value
insert_max_col(Affects_Version_index,Field[0])
# Obtain all current "Field" index in "Csv_content_edited" list
first_row_updated = Csv_content_edited[0]
fields_index = search_field_index(Field,first_row_updated)
# Obtain the index of "Affects_Version" in in "Csv_content_edited" list
Fix_Version_index = fields_index[Field[1]]
# insert the matching value
insert_max_col(Fix_Version_index,Field[1])
# Obtain all current "Field" index in "Csv_content_edited" list
first_row_updated = Csv_content_edited[0]
fields_index = search_field_index(Field,first_row_updated)
# Obtain the index of "Affects_Version" in in "Csv_content_edited" list
Fix_Version_index = fields_index[Field[2]]
# insert the matching value
insert_max_col(Fix_Version_index,Field[2])
# Obtain the final edited list.
return Csv_content_edited
# Write the csv file.
def writeContent():
with open(new_file_name,'wb') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerows(readContent(file_name))
# Execute the finnal function.
if __name__ == '__main__':
try:
writeContent()
except (IOError,NameError,IndexError):
print "Please type the correct file name. e.g: '" + sys.argv[0] + " testfile.csv'"
else:
print 'The result file is: %s' %new_file_name
处理前的效果
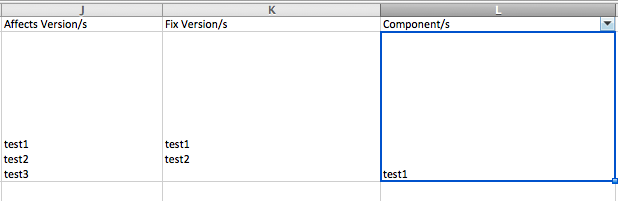
处理后的效果

如有雷同,纯属扯淡...
正文部分到此结束
版权声明:除非注明,本文由(showerlee)原创,转载请保留文章出处!
本文链接:http://www.showerlee.com/archives/1418
本文链接:http://www.showerlee.com/archives/1418
继续浏览:PYTHON


还没有评论,快来抢沙发!